
golang 온라인 스터디 때 제가 준비한 파트에 대한 자료를 공유드립니다.
Queuing
Sometimes it’s useful to begin accepting work for your pipeline even though the pipeline is not yet ready for more. This process is called queuing.
All this means is that once your stage has completed some work, it stores it in a temporary location in memory so that other stages can retrive it later, and your stage doesn’t need to hold a reference to it.
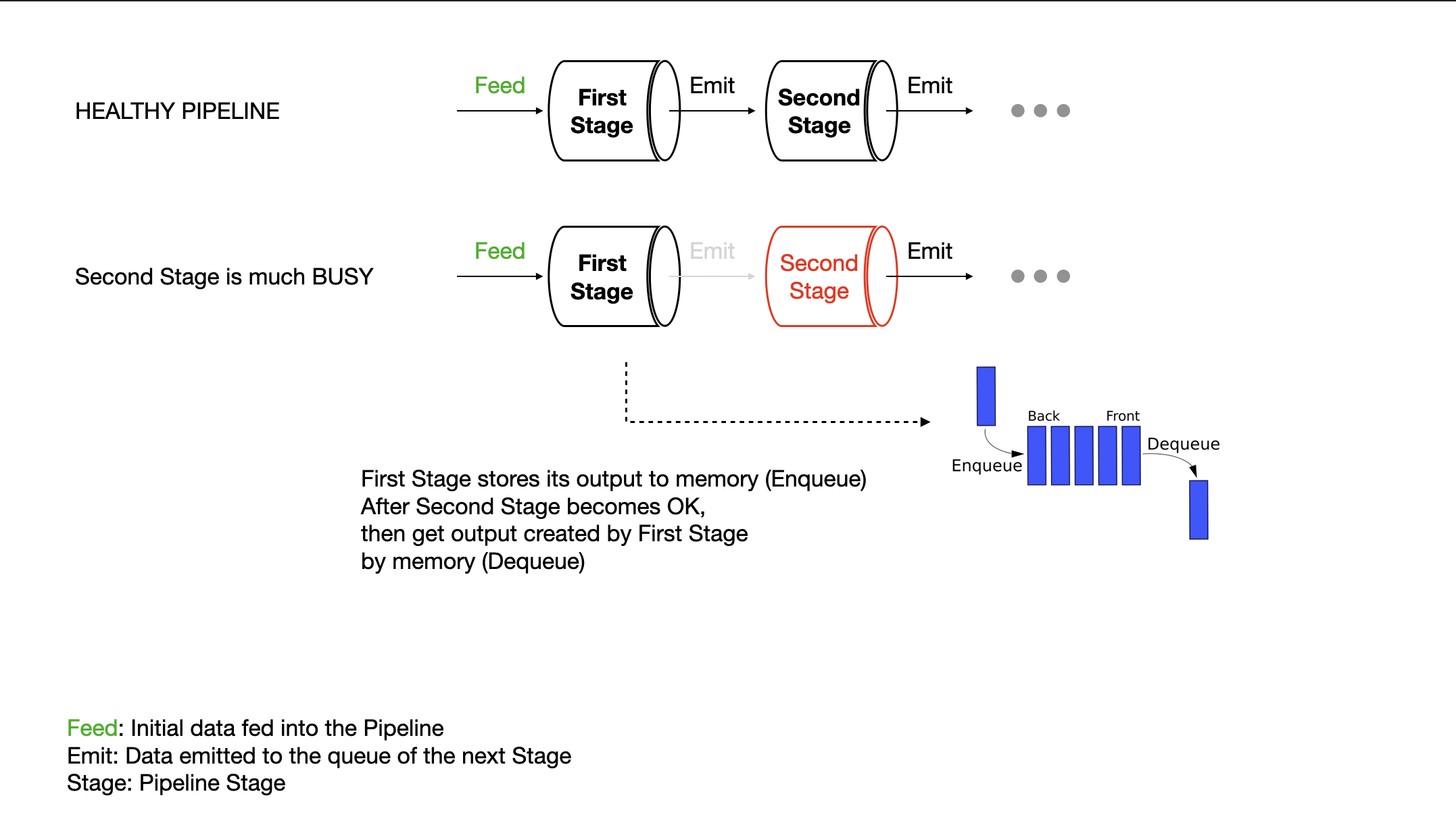
Queuing will almost never speed up the total runtime of your program; it will only allow the program to behave differently.
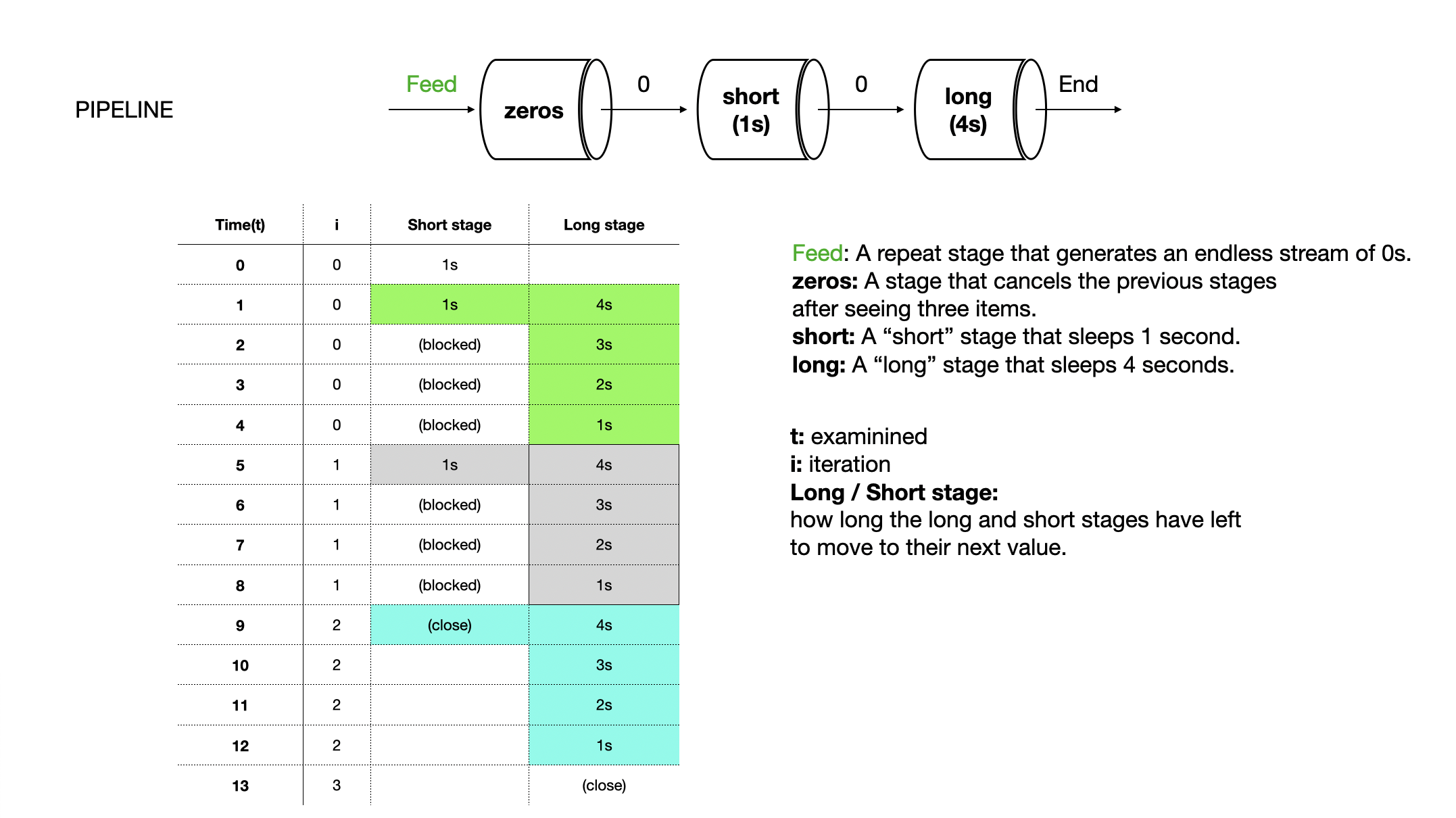
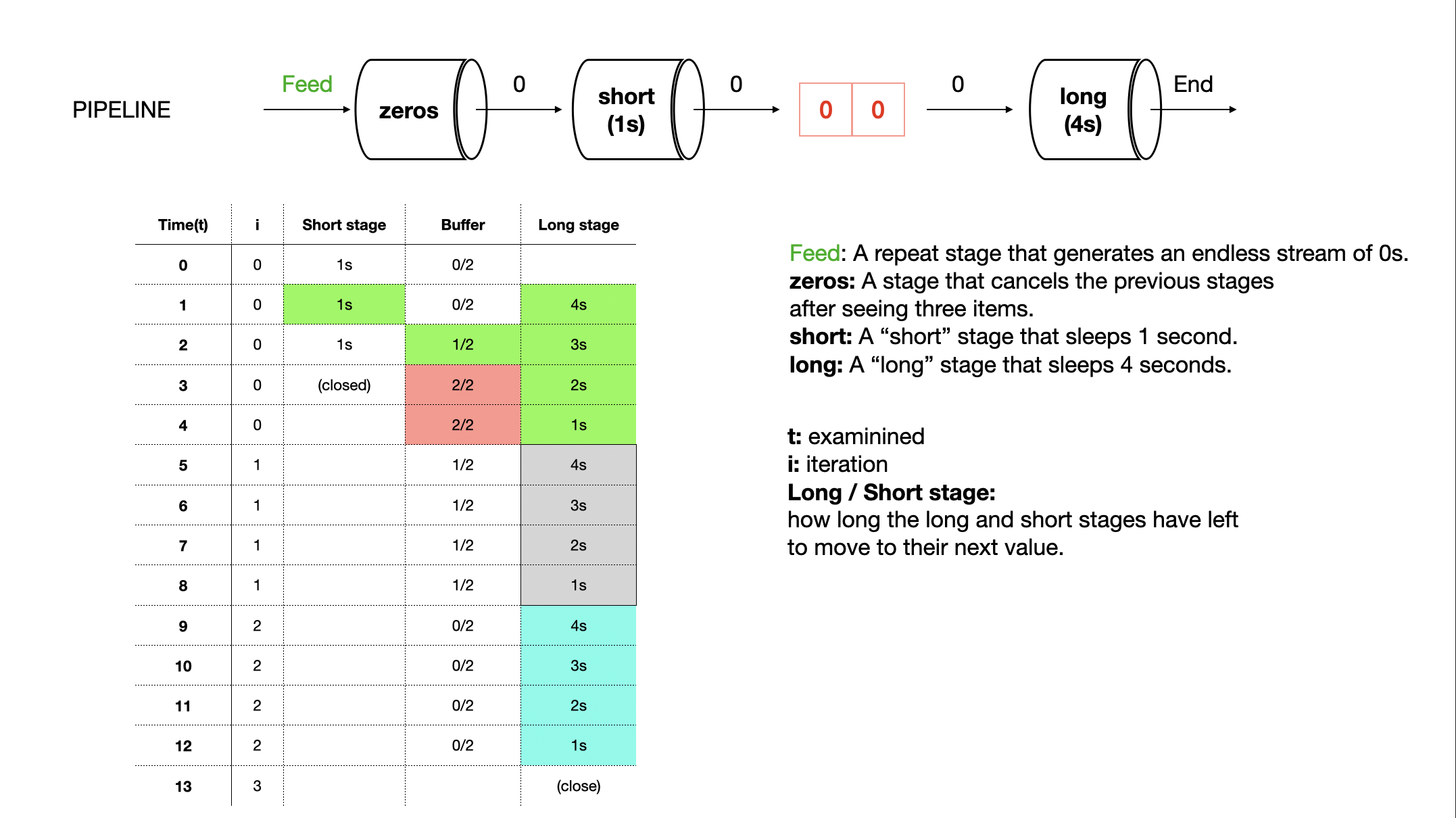
The entire pipeline still took 13 seconds! But look at the short stage’s runtime. It’s complete after onlly 4 seconds as opposed to the 9 seconds it took previously. We’ve cut this stage’s runtime by two thirds! But if the entire pipeline still takes 13 seconds to execute, how does this help us?
Ans: The utility of introducing a queue isn’t that the runtime of one of stages has been reduced, but rather that the time it’s in a blocking state is reduced. This allows the stage to continue doing its job.
In this way, the true utility of queues is to decouple stages so that the runtime of one stage has no impact on the runtime of another. Decoupling stages in this manner then cascades to alter the runtime behavior of the system as a whole, which can be either good or bad depending on your system.
Let’s begin by analyzing situations in which queuing. Where should be queues be placed? What should the buffer size be?
- If batching requests in a stage saves time.
- If delays in a stage produce a feedback loop into the system
Buffers input in something faster (e.g., memory) than it is designed to send to (e.g., disk).
buffer_test.go
Finished after work 1 times
goos: darwin
goarch: amd64
BenchmarkUnbufferedWrite-8 Finished after work 100 times
Finished after work 10000 times
Finished after work 240836 times
240836 4335 ns/op
Finished after work 1 times
BenchmarkBufferedWrite-8 Finished after work 100 times
Finished after work 10000 times
Finished after work 1000000 times
1000000 1002 ns/op
PASS
ok command-line-arguments 3.088s
Buffered write is faster than the unbuffered write. This is because in bufio.Writer, the writes are queued internally into a buffer until a sufficient chunk has been accumulated, and then the chunk is written out. The process is often called chunking, for obvious reasons.
Chunking is faster because bytes.Buffer must grow its allocated memory to accommodate the bytes it must store. Growing memory is expensive; therefore, the less times we have to grow, the more efficient our system as a whole will perform. Thus, queuing has increased the performance of your system as a whole.
“Each write is ultimately a syscall and if doing frequently can put burden on the CPU. Devices like disks work better dealing with block-aligned data. To avoid the overhead of many small write operations Golang is shipped with bufio.Writer. Data, instead of going straight to destination (implementing io.Writer interface) are first accumulated inside the buffer and send out when buffers is full: producer –> buffer –> io.Writer”
Queuing should be implemented either:
- At the entrance to your pipeline.
- In stages where batching will lead to higher efficiency.
L = the average number of units in the system.
Labmda = the average arrival rate of units.
W = the average time a unit spends in the system.
(I NEED A HELP)
파이프라인에서 안정적인 시스템은 ingress와 egress의 비율이 동일하다. ingress의 비율이 egress의 비율을 넘어서면 시스템은 불안정한 것이고 death-sprial에 진입한다. ingress가 egress보다 작아도 여전히 불안정한 시스템이다. 다만 위와 다른 건, 리소스를 완전히 사용하지 않다고 있는 것뿐이다.
위 수식의 결론: 전체 파이프라인의 속도는 가장 느린 단계에 의해 결정된다.
References:
introduction-to-bufio-package-in-golang
The context Package
We’ve looked at the idiom of creating a done channel, which flows through your program and cancels all blocking concurrent operations. This works well, but it’s also somewhat limited.
It would be useful if we could communicate extra information alongside the simple notification to cancel: why the cancellation was occuring, or whether or not our function has a deadline by which it needs to complete.
The context package serves two primary purposes:
- To provide an API for canceling branches of your call-graph.
- To provide a data-bag for transporting request-scoped data through your call-graph.
And the context package helps manage belows also:
- A gouroutine’s parent may want to cancel it.
- A goroutine may want to cancel its children.
- Any blocking operations within a goroutine need to be preemptable so that it may be canceled.
The Context type will be the first argument to your function.
Instances of context.Context may look equivalent from the outside ,but internally they may change at every stack-frame. For this reason, it’s important to always pass instances of Context into your functions. This way functions have the Context intended for it, and not the Context intended for a stack-frame N levels up the stack.
Let’s look at an example that uses the done channel patter, and see what benefits we might gain from switching to use of the context package.
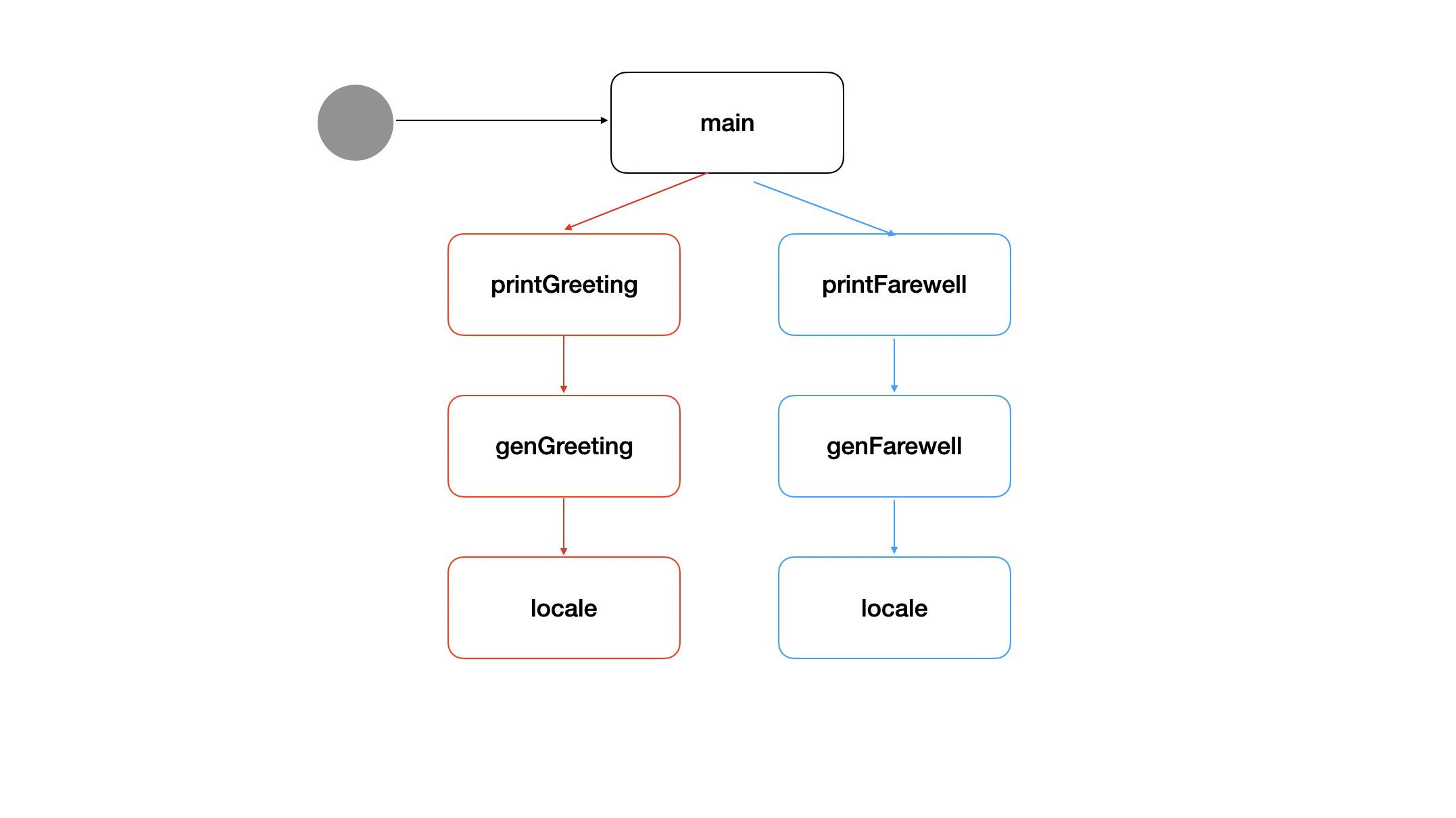
01_done_channel_pattern
We’ve set up the standard preemption method by creating a done channel and passing it down through our call-graph. If we close the done cahnnel at any point in main, both branches will be canceled.
We wouldn’t have the extra information about deadlines and errors a Context gives us.
02_context_greeting
1: Here main creates a new Context with context.Background() and wraps it with context.WithCancel to allow for cancellation.
2: On this line, main will cancel the Context if there is an error returned from printGreeting.
3: Here genGreeting wraps its Context with context.WithTimeout. This will automatically cancel the returned Context after 1 second, thereby canceling any children it passes the Context into, namely locale.
- This line returns the reason why the Context was canceled. This error will bubble all the way up to
main, which will cause the canllation at 2.
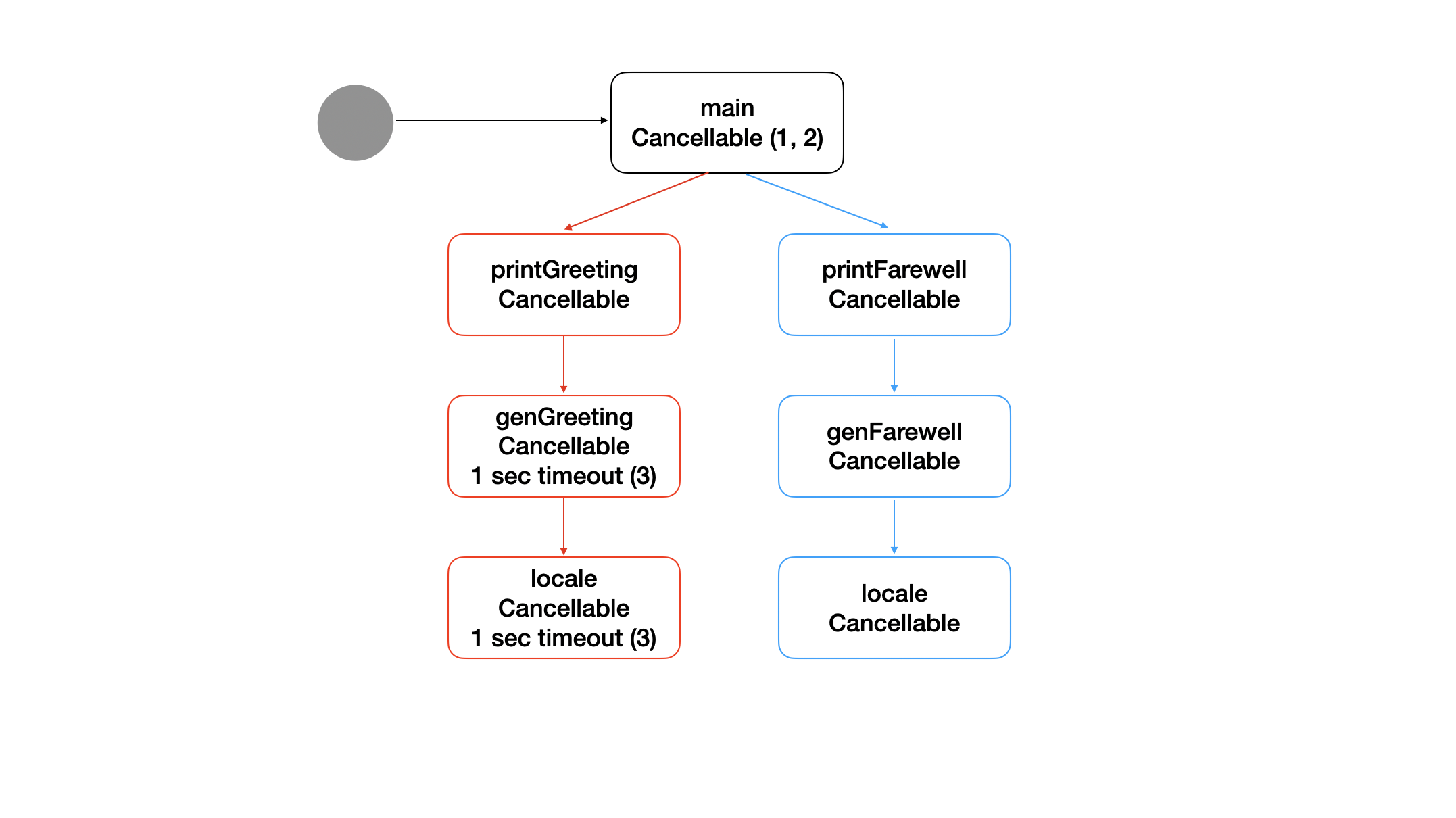
cannot print greeting: context deadline exceeded
cannot print farewell: context canceled
locale이 실행하는 데 최소 1분이 걸리기 때문에, genGreeting의 호출은 항상 제한 시간이 초과될 것이고, 이것은 main이 항상 printFarewell 아래의 호출 그래프를 취소한다는 것을 의미한다.
이 프로그램을 더 개선할 수도 있다. locale이 실행되는 데 약 1분이 걸린다는 점을 알고 있으므로 locale 내부에서 마감 시한이 주어졌는지를 확인할 수 있고, 마감 시한에 거릴지도 확인할 수 있다.
03_context_deadline
1: Context에 마감 시한이 주어졌는지 확인한다. 마감 시한이 주어졌고, 시스템 클록이 마감 시한을 넘겼다면 context 패키지에 정의된 특별한 에러인 DeadlineExceeded를 리턴한다.
“하위의 호출 그래프가 얼마나 오래 걸리는지 알고 있어야 한다는 점인데, 이를 어떻게 달성할 수 있을까?”
요청 범위 데이터를 저장하고 조회할 수 있는 Context용 데이터 저장소를 사용할 수 있다.
04_context_data
Context의 키와 값이 interface{}로 정의돼 있기 때문에, 값을 검색할 때 Go의 타입 안전성을 잃어버리게 된다.
이러한 이유로 Context에서 값을 저장하고 조회할 때는 패키지에 맞춤형 키 타입을 정의하는 것이 좋다.
05_context_key_type
foo type과 bar type은 분명 근본적으로 같은 값임에도 불구하고 따로 구분되는 것을 확인할 수 있다.
데이터를 저장하는 데 사용하는 키를 외부로 내보내지 않는 대신 데이터를 검색하는 함수는 사용할 수 있게끔 해야한다.
06_context_retrieval
타입에 안전한 방식으로 Context에서 값을 조회할 수 있는 방법을 확보했다. 그러나 이 기법의 문제는, Context에 키를 저장하는 데 사용되는 타입이 비공개이기 때문에 다른 패키지에서 해당 데이터를 조회할 수 있는 방법이 없다는 것이다. 이로 인해 여러 위치에서 가져온 데이터 타입을 중심으로 패키지를 생성하는 아키텍처를 강제할 수밖에 없다.